Software is correct if it acts as specified. It is robust if it can take a high load until it goes down. Software is resilient if it can go back to normal after a disruption. The disruption could be a power outage, a temporary network outage, a full disk, or a web service that is temporarily not reachable. There are patterns to deal with those issues. Learn them, use them!
1. Fallback
You probably know it: You’re commuting, reading your favorite articles on your smartphone when the connection drops. You enter your favorite blog URL — martin-thoma.com, I hope — but you only get to know that you lost the internet connection:
Your browser cannot get any information from the internet without a connection. Obviously. But what could it do instead?
Google Chrome shows you a mini-game. It tries to inform you what you could possibly do to fix it and you can choose to play with the dinosaur. The dinosaur game is not what you wanted, but a neat fallback.
In other contexts, fallbacks are called a “fail-safe”. The dead man’s switch in trains is one concrete example. The train driver has to press a pedal in regular intervals to show that he is ok and paying attention. If the train driver does not press the dead man’s switch, the train performs an emergency stop.
2. Retry
While you’re playing the mini-game, the browser can still try to get the website. Maybe your connection is unstable. This means you have a connection once in a while. The browser can try to get what you need in the background and support you with offline reading when you want to go back. Not ideal, but a good fallback. Better than the mini-game.
To get to this improved fallback, the browser has to retry to get to the website.

{kind=link}
Yes, that is a pattern. A trivial one, but an important one. I‘ve used it when sending web requests. If you receive an error, try again. The Python requests library has a built-in max_retries argument for some of the error cases.
In some cases, you deal with changing state. Now it becomes tricky. Maybe you don’t really know if the request before failed? Can you risk executing the request twice? The property you want is idempotency: f(x) = f(f(x)). Applying the function twice yields the same result as applying it once.
For example, if you have a money transfer like “Martin sends 50 EUR to Anna”, it’s not idempotent. If you have “Execute transaction XYZ, if not executed before”, it is. However, now you need to make sure that you have a locking mechanism and that all transactions have unique IDs.
Retrying to connect to a failing service comes with its own problems. You might make it harder for the service to get back to normal. For this reason, you might want to consider capped exponential backoff:
max_sleep = 300 # seconds
base_sleep = 2 # seconds
sleep_time = min(max_sleep, base ** attempts)
In order to prevent multiple services essentially hitting at the same time, you can add a jitter:
max_sleep = 300 # seconds
base_sleep = 2 # seconds
jitter = random(0, 5) # seconds
sleep_time = min(max_sleep, base ** attempts) + jitter
3. Timeout and other Resource Limitations
At some point, you need to accept that something is broken. But when do you do that? A common default is to wait for a response from a web service for 30 seconds. That is really long. In many cases, you want a timeout way sooner. The timeout basically means that you accept that something went wrong. After the timeout, you can retry or use a fallback.
Limiting the possible execution time for one function, process, or program is also of advantage in other situations. The Google Code Jam pops into my mind. It’s an open competition in which developers submit code to tasks given by Google. Those solutions might have flaws that lead to infinite loops. This means if Google executes those solutions, they need to limit the potential execution time.
A watchdog can monitor the responsiveness of the overall system and restart everything in case the system becomes unresponsive. Web services, for example, typically have a /health endpoint that responds with something trivial, e.g. the constant string "healthy" or the current system time. If the response does not come or takes too long, the system is marked as “unhealthy”. If it’s unhealthy for too long, the Docker container is restarted.
Another resource you might want to limit is memory and disk. Think about anti-virus software that wants to check a ZIP archive. The archive might be a ZIP bomb: ZIP Bombs 💣😈 Make your storage explode 💥infosecwriteups.com
By limiting both resources you make sure you’re not vulnerable to this issue.
4. Circuit Breaker
 Photo of a two-pole circuit breaker on Wikimedia Commons by Dmitry G
Photo of a two-pole circuit breaker on Wikimedia Commons by Dmitry G
{kind=link}
If something is wrong with the electricity in one room of your house, e.g. one part is having a short-circuit or consuming too much power, you want everything else to still work.
In the case of software, you might think of a web service A which uses a web service B. Now A notices that B starts getting slower and slower. Now A could just send all requests to B and handle the potential timeouts. However, it can also notice that B is having issues. A stops sending normal requests to B, giving B time to recover. This means there needs to be a mechanism to check if B is healthy again. That could be just a health-endpoint. Or it could be a throttled mode at A where response times are automatically measured.
The circuit-breaker pattern goes slightly beyond the capped exponential backoff with jitter. It tracks requests over multiple sources.
5. Rate Limiting
We’ve talked about the retry pattern with capped exponential backoff and circuit breaker pattern as ways to be “good neighbors”, trying to protect the services they use.
However, not every user is such a good neighbor. They might not intentionally try to harm you, but maybe a developer is not aware that they are using an endpoint which causes a lot of work. You might want to be able to limit how the API is used — especially if it’s public.
6. Redundancy
Servers can fail due to breaking hardware, power outages, a fire in the data center, or network outages due to construction work to name just a few reasons. Having redundancy makes the system more robust against those rare events.
For hard disks, we have various RAID levels. For APIs, we can start multiple instances and have a round-robin load balancing.
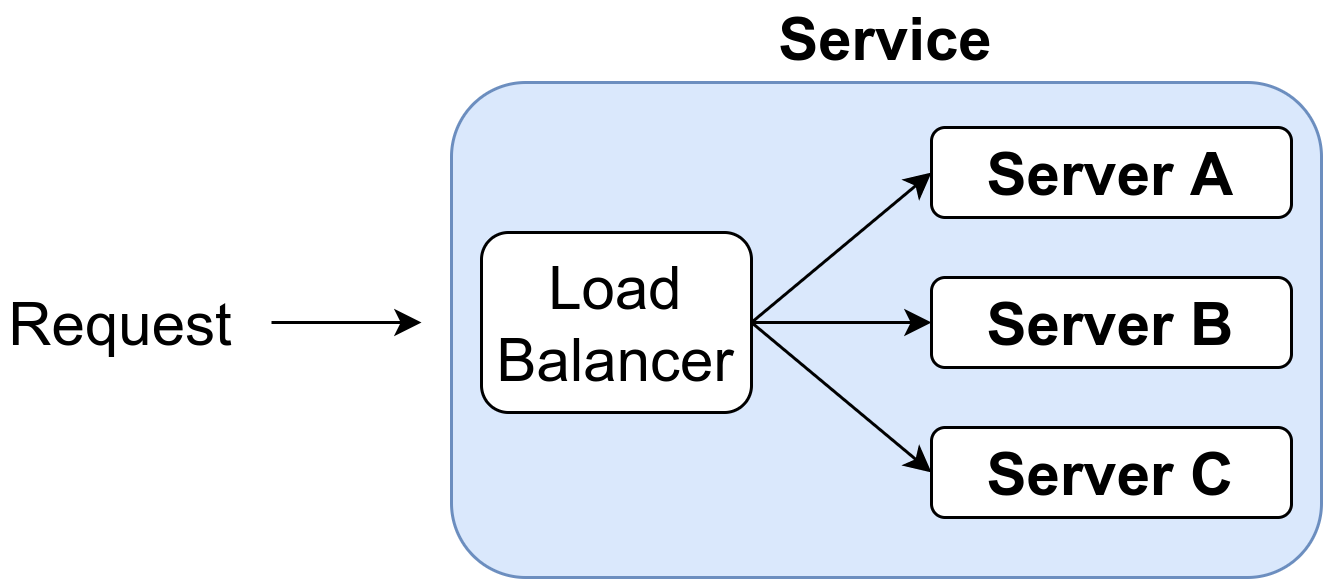
Let’s say each server is 99.0% available. That means it is down for 3.65 days each year. If you have a redundant system where servers run in parallel as outlined above, the service is still up when at least one server is up. That means the availability increases to 1-(1-p)^n where n is the number of servers and p is the availability of one server. Let’s see how those numbers change with n:
- n=1: The service is 99.0% available. That’s 3.65 days of downtime per year.
- n=2: The service is 99.99% (“four nines”) available. That’s 52 minutes of downtime per year.
- n=3: The service is 99.9999% (“six nines”) available. That’s 31 seconds of downtime per year.
This assumes that a single server going down does not harm the others — which is unlikely, as the load will increase.
You should also note that this is for services that run in parallel and can replace each other. If you have services that rely on each other the formula changes to $p^n$:
- n=1: The service is 99.0% available. That’s 3.65 days of downtime per year.
- n=2: The service is 98.01% available. That’s 7.27 days of downtime per year.
- n=3: The service is 97.03% available. That’s 10.8 days of downtime per year.
Spinning up such parallel machines is easy if you don’t need to store or modify state. It’s a lot harder for databases.
I’ve mainly written about servers here, but you can also think of error-correcting codes in the case of network communication and storage also is the redundancy pattern.
7. Bulkhead
Bulkheads provide boundaries across which failures do not propagate. For example, think of YouTube. Users can upload videos and the videos get re-encoded. Executing this task on a separate machine guarantees that no issues with disk space, memory usage, CPU usage, and potential exploits in the used libraries affect the rest of the system. Having the software run of a separate machine is one form of sandboxing. We can guarantee by this strong isolation that this single feature will not affect others.
8. Caching
I have a love-hate relationship with caching. On the one hand, caches reduce the load on your servers A LOT. They provide a nice fallback as well. On the other hand, you need to deal with inconsistencies introduced by caching. Maybe you need to explicitly invalidate the caches.
Adrian Hornsby wrote a nice article about caching for resilience: Patterns for Resilient Architecture — Part 4 Caching for Resiliencymedium.com
9. Boundary Validation
You want to make sure that the input to your service is structured as expected and that you provide the output you promised. You can use libraries like pydantic to clearly define models of what you expect as input. Checking parameters is important. If something is not as expected, you should fail early. If an external API has changed its response types, e.g. from float to string, you want to know this early. In the best case, you can even convert it automatically. If you received a complex dictionary and the service changed deep down how the response is structured, having clear models helps a lot.
For external systems, you want to clearly separate the input model from the rest. This should at least be its own module or class. If it’s something bigger, maybe even its own library or an internal service that wraps the external service.
10. Rollbacks
It’s not always the external world that makes our software fail. Programming mistakes we developers introduce have their fair share as well. In fact, I would argue that no non-trivial system is bug-free. Some bugs are acceptable, others are not. And some bugs are so problematic, that they need to be fixed ASAP.
This is where rollbacks come into play. A rollback means to jump back to a stable system state. I know them from two fronts: Either from a version control system like git where a previous release that is known to work is restored. Or from a systems perspective, e.g. using the OpenShift Container Platform. Every service is running in a Docker container. Updating a service means adding a new image and changing the service:latest tag. If a service is never healthy, the last known healthy image is used.
Summary
The presented design patterns can be grouped:
- Detection: Get to know that something is wrong.
TimeoutsandChecksumsarein this category. - Containment: Make sure the errors don’t affect other systems and limit
the impact on the user. The patterns in this category are
Fallback,Resource Limitation,Circuit Breaker,Bulkhead,Caching - Recovery: Get back up. Retry and Rollback are in this category
- Prevention: Avoid getting into trouble in the first place.
Rate Limiting,Redundancy,Caching, andBoundary Validationdo that.
I hope this was helpful to you!
Resources
- Sazzad Hissain Khan: “Distinguishing System Robustness, Resilience, Stability, Flexibility and Performance”, 2019.
- Saurabh Hukerikar, Christian Engelmann: “Resilience Design Patterns: A Structured Approach to Resilience at Extreme Scale”