PyPI, the Python Package Index, gives a very crappy but simple interface to query metadata about its packages. I scrapped all of the packages metadata. 53,533 packages were scrapped (date: 2015-01-18), because I wanted to see if there is malware on PyPI (related to this question on security.SE).
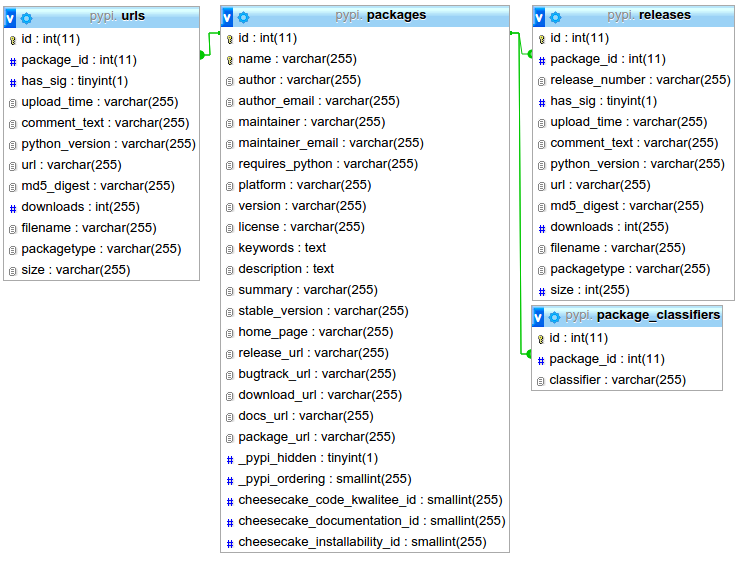
The database looks like this:
Exploring the data
When I scapped the data from PyPI, I made all database fields "varchar 255" as there seems to be no information about the possible values. Then I explored the data
name: The longest package name is 80 characters long (Aaaaaaaaaaa...), the shortest packages have only one character.author: 911× "UNKOWN", 741× empty, 195× "None", 151× "Zope Foundation and Contributors". There are about 22,000 different authors. There are 595 authors who wrote more than 10 packages.author_email: 2059× "UNKOWN", 932× empty, 323× "[email protected]", 216× "None" and 204× "TODO".maintainer: 46879× "None", 5507× empty, 17× Paul Boddie.requires_python: 53467× "None", 3× "UNKNOWN", 2× ">=2.7,!=3.0,!=3.1", 2× ">=2.5", 1× "2.6", 1× ">= 3.3", 1× ">=2.4", 1× ">= 2.7" - that's it. No other values. Seems as if this is pretty much useless.docs_url: Either begins withhttp://pythonhosted.orgor is empty.
Most active authors
SELECT
`author`, COUNT(`id`) as `created_packages`
FROM
`packages`
GROUP BY
`author`
ORDER BY
COUNT(`id`) DESC, `author` ASC
LIMIT
50
gives
| 1485 | |
|---|---|
| UNKNOWN | 1150 |
| None | 196 |
| OpenStack | 188 |
| Zope Foundation and Contributors | 146 |
| MicroPython Developers | 139 |
| OpenERP SA | 137 |
| Zope Corporation and Contributors | 128 |
| RedTurtle Technology | 127 |
| Praekelt Foundation | 126 |
| Fanstatic Developers | 98 |
| Tryton | 98 |
| Raptus AG | 97 |
| russianidiot | 93 |
| hfpython | 92 |
| LOGILAB S.A. (Paris, FRANCE) | 88 |
| BlueDynamics Alliance | 87 |
| Ralph Bean | 83 |
| JeanMichel FRANCOIS aka toutpt | 69 |
| Bart Thate | 68 |
The total number of authors is 28 183 (06.12.2015):
SELECT COUNT(DISTINCT `author`) AS `total_authors` FROM `packages`
Maximum Length
I guess many values are stored on PyPI as Varchar(255). To check if I might
have missed some values, I checked which entry was the longest one for all
columns. I did this with
SELECT `name`, LENGTH(`name`) FROM `packages` ORDER BY LENGTH(`name`) DESC
| Column | Maximum Length | Entry |
|---|---|---|
| name | 80 | Aaaaaaaaaaaaaaaaaaa-aaaaaaaaa-aaaaaaasa-aaaaaaasa-aaaaasaa-aaaaaaasa-bbbbbbbbbbb |
| author | 248 | Michael R. Crusoe, Greg Edvenson, Jordan Fish, Adina Howe, Luiz Irber, Eric McDonald, Joshua Nahum, Kaben Nanlohy, Humberto Ortiz-Zuazaga, Jason Pell, Jared Simpson, Camille Scott, Ramakrishnan Rajaram Srinivasan, Qingpeng Zhang, and C. Titus Brown |
| author_email | 215 | [email protected], [email protected], [email protected], [email protected], [email protected], [email protected], [email protected], [email protected], [email protected], [email protected], [email protected] |
| maintainer | 63 | Panagiotis Liakos, Katia Papakonstantinopoulou, Michael Sioutis |
| maintainer_email | 67 | [email protected], [email protected], [email protected] |
| requires_python | 17 | >=2.7,!=3.0,!=3.1 |
| platform | 231 | Natural Language :: English License :: OSI Approved :: Apache Software License Environment :: Console Development Status :: 2 - Pre-Alpha Intended Audience :: Developers Programming Language :: Python :: 2.7 Topic :: Database |
| version | 73 | [In Progress] Python middle layer for interacting with Redis data easily. |
| license | 466 | Copyright © 2014 ЗАО “БАРС Груп” Данная лицензия разрешает лицам, получившим копию данного программного обеспечения и сопутствующей документации (в дальнейшем именуемыми «Программное Обеспечение»), безвозмездно использовать Программное Обеспечение без ог |
| keywords | 655 | ArcLink,array,array analysis,ASC,beachball,beamforming,cross correlation,database,dataless,Dataless SEED,datamark,earthquakes,Earthworm,EIDA,envelope,events,FDSN,features,filter,focal mechanism,GSE1,GSE2,hob,iapsei-tau,imaging,instrument correction,instrument simulation,IRIS,magnitude,MiniSEED,misfit,mopad,MSEED,NERA,NERIES,observatory,ORFEUS,picker,processing,PQLX,Q,real time,realtime,RESP,response file,RT,SAC,SEED,SeedLink,SEG-2,SEG Y,SEISAN,SeisHub,Seismic Handler,seismology,seismogram,seismograms,signal,slink,spectrogram,StationXML,taper,taup,travel time,trigger,VERCE,WAV,waveform,WaveServer,WaveServerV,WebDC,web service,Winston,XML-SEED,XSEED |
| description | 65535 | [id don't want to put that here - there were 22 with this length] |
| summary | 278 | Splits one vcard file (*.vcf) to many vcard files with one vcard per file. Useful for import contacts to phones, thats do not support multiple vcard in one file. Supprt unicode cyrillic characters. Консольная программа для р |
| stable_version | 4 | None |
| home_page | 134 | http://127.0.0.1:8888/USK@9X7bw5HD2ufYvJuL3qAVsYZb3KbI9~FyRu68zsw5HVg,lhHkYYluqHi7BcW1UHoVAMcRX7E5FaZjWCOruTspwQQ,AQACAAE/pyfcp-api/0/ |
| release_url | 130 | http://pypi.python.org/pypi/softwarefabrica.django.appserver/1.0dev-BZR-r10-panta-elasticworld.org-20091023132843-vitk6k7e5qlvhej5 |
| bugtrack_url | 104 | https://bugzilla.redhat.com/buglist.cgi?submit&component=python-nss&product=Fedora&classification=Fedora |
| download_url | 183 | http://pypi.python.org/packages/source/s/softwarefabrica.django.appserver/softwarefabrica.django.appserver-1.0dev-BZR-r10-panta-elasticworld.org-20091023132843-vitk6k7e5qlvhej5.tar.gz |
| package_url | 108 | http://pypi.python.org/pypi/Aaaaaaaaaaaaaaaaaaa-aaaaaaaaa-aaaaaaasa-aaaaaaasa-aaaaasaa-aaaaaaasa-bbbbbbbbbbb |
| _pypi_hidden | - | True or False |
| _pypi_ordering | - | Integers from 0 to 464 |
| cheesecake_code_kwalitee_id | - | Integers from 183 to 6513 and None values |
| cheesecake_documentation_id | - | Integers from 182 to 6512 and None values |
| cheesecake_installability_id | - | Integers from 181 to 6511 and None values |
We can see multiple problems here:
- URLs: localhost / 127.0.0.1 is almost certainly not desired
cheesecake_installability_id,cheesecake_documentation_id,cheesecake_code_kwalitee_idshould have NULL and None should be casted to NULL. The data type is likely to be numeric._pypi_orderingshould be numeric_pypi_hiddenshould be boolean
So I changed the types in the database. Let's continue.
What people don't use
All metadata is provided by the authors of the packages. Some fields, like the package name or the description, are used very often, but some fields are only rarely used:
Maintainer
maintainer and maintainer_email is interesting for people who want to send
bug reports. If this is empty, I would guess the package is dead.
Platform
SELECT
`platform`, COUNT(`id`)
FROM
`packages`
GROUP BY
`platform`
ORDER BY
COUNT(`id`) DESC
gives 759 different results. The TOP-10 were
| Platform | Count |
|---|---|
| UNKNOWN | 43539 |
| any | 3515 |
| 1986 | |
| Any | 635 |
| OS Independent | 542 |
| None | 265 |
| Linux | 225 |
| linux | 167 |
| Posix; MacOS X; Windows | 157 |
| POSIX | 156 |
You can see that there are alternative ways to express the same thing. Also, the ";" should not be here as the manual states it should be a list.
The manual is also too short for this entry. It only says "a list of platforms" which seems to be pretty much useless.
docstore.mik.ua gives a little bit more information
A list of platforms on which this distribution is known to work. You should provide this information if you have reasons to believe this distribution may not work everywhere. This information should be reasonably concise, so this field may refer for details to a file in the distribution or to a URL.
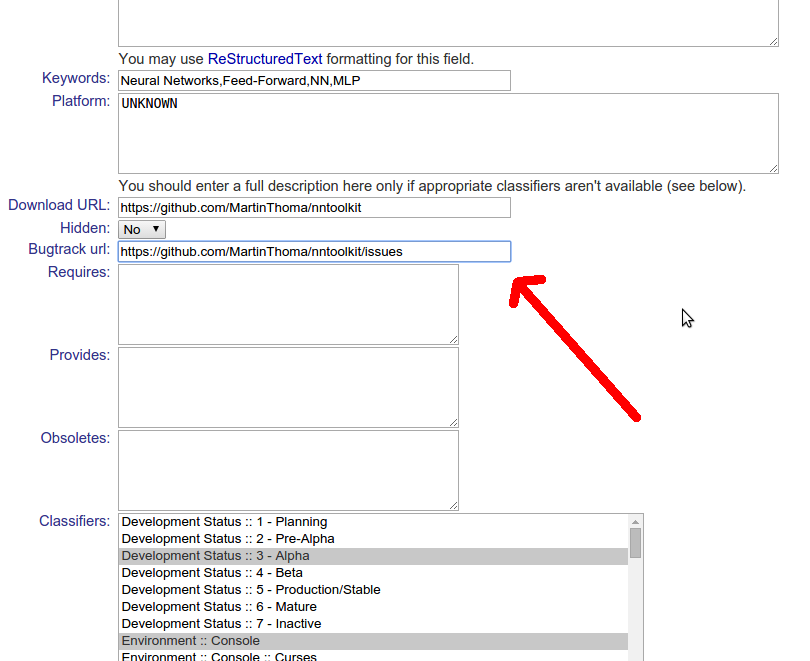
Bugtracker
This one is very important. Users should have an easy possibility to report bugs. So please help them by added your bug tracker URL wherever it makes sense. Here is how you add it on PyPI:
License
Another important one. Add a license to your software!
SELECT
`license`, COUNT(`id`)
FROM
packages
GROUP BY
`license`
ORDER BY
COUNT(`id`) DESC
gives
| License | Count |
|---|---|
| UNKNOWN | 11444 |
| MIT | 8098 |
| BSD | 7224 |
| GPL | 4202 |
| MIT License | 1410 |
| (empty) | 1398 |
| LICENSE.txt | 1201 |
| GPLv3 | 1083 |
| LGPL | 833 |
| ZPL 2.1 | 829 |
| BSD License | 811 |
| Apache License 2.0 | 482 |
| Apache License, Version 2.0 | 443 |
| Apache 2.0 | 437 |
| GPLv2 | 370 |
| None | 363 |
| ZPL | 288 |
| GPL-3 | 272 |
| GPLv3+ | 258 |
| LICENSE | 249 |
and about 6500 other licenses. Most might be variants in writing, e.g.
- Apache License 2.0
- Apache License, Version 2.0
- Apache 2.0
are all the same license. Some packages have no licence (Unknown and empty).
Many are invalid values, like
- LICENSE.txt
- None
- LICENSE
- Python
These indicate that people have no idea what to input there. tldrlegal.com might help in that case. I think the Python community should try to eliminate variants in writing license names as it makes finding, filtering and analyzing packages more difficult.
Classifiers
Python makes use of so called trove classifiers. They are defined in PEP 301 and listed here.
The following table gives the TOP-10 most commonly used classifiers:
| Classifier | Percentage |
|---|---|
| Programming Language :: Python | 0.4615 |
| Intended Audience :: Developers | 0.4412 |
| Operating System :: OS Independent | 0.3229 |
| Programming Language :: Python :: 2.7 | 0.2183 |
| Topic :: Software Development :: Libraries :: Pyth... | 0.2038 |
| Development Status :: 4 - Beta | 0.2038 |
| License :: OSI Approved :: BSD License | 0.1632 |
| License :: OSI Approved :: MIT License | 0.1529 |
| Environment :: Web Environment | 0.1487 |
| Programming Language :: Python :: 2.6 | 0.1306 |
When you analyze the licenses with the trove classifiers you get a different image:
SELECT
`classifier`, COUNT(`id`) / 53533
FROM
`package_classifiers`
WHERE
`classifier` LIKE "License%"
GROUP BY
`classifier`
ORDER BY
COUNT(`id`) DESC
| License | Percentage |
|---|---|
| License :: OSI Approved :: BSD License | 0.1632 |
| License :: OSI Approved :: MIT License | 0.1529 |
| License :: OSI Approved :: GNU General Public License (GPL) | 0.0625 |
| License :: OSI Approved :: Apache Software License | 0.0460 |
| License :: OSI Approved :: GNU Library or Lesser General Public License (LGPL) | 0.0188 |
There are 94 trove classifiers with five or less packages which use this classifier. I guess many of them are not in the official list of classifiers.
Package type
SELECT
`packagetype`, COUNT(`id`)
FROM
`urls`
GROUP BY
packagetype
ORDER BY
COUNT(`id`) DESC
gives
| Package type | Count |
|---|---|
| sdist | 47649 |
| bdist_egg | 4933 |
| bdist_wheel | 3098 |
| bdist_wininst | 1512 |
| bdist_dumb | 577 |
| bdist_msi | 45 |
| bdist_rpm | 35 |
| bdist_dmg | 4 |
Can anybody explain what this means?
Downloads
SELECT
`name`, `url`, `downloads`
FROM
`urls`
JOIN
`packages` ON `urls`.`package_id` = `packages`.`id`
ORDER BY
`urls`.`downloads` DESC
LIMIT 10
gives
| Package type | Count |
|---|---|
| wincertstore | 10026403 |
| ssl | 8987455 |
| pyasn1 | 8655361 |
| Paste | 8401111 |
| PyYAML | 7180547 |
| distribute | 6276421 |
| MarkupSafe | 6215382 |
| ecdsa | 6030395 |
| meld3 | 5715687 |
| pika | 5567400 |
and
SELECT
`name`, SUM(`downloads`)
FROM
`releases`
JOIN
`packages` ON `releases`.`package_id` = `packages`.`id`
GROUP BY
`name`
ORDER BY
SUM(`downloads`) DESC
LIMIT 10
| Package type | Count |
|---|---|
| setuptools | 45485205 |
| requests | 35446321 |
| virtualenv | 35039299 |
| distribute | 34779943 |
| boto | 29678066 |
| six | 28253705 |
| certifi | 27381407 |
| pip | 26266325 |
| wincertstore | 24831145 |
| lxml | 20901298 |
Size
What is the biggest Python package?
SELECT
`name`, `release_number`, `size`
FROM
`releases`
JOIN
`packages` ON `releases`.`package_id` = `packages`.`id`
ORDER BY
`releases`.`size` DESC
LIMIT 30
| Package | Version | Size |
|---|---|---|
| de422 | 2009.1 | 545298406 |
| de406 | 1997.1 | 178260546 |
| scipy | 0.13.3 | 62517637 |
| appdynamics-bindeps-linux-x86 | 5913-master | 57861536 |
| appdynamics-bindeps-linux-x64 | 5913-master | 56366211 |
| python-qt5 | 0.1.5 | 56259023 |
| python-qt5 | 0.1.8 | 56237972 |
| pycalculix | 0.92 | 56039839 |
| wltp | 0.0.9-alpha.3 | 55414544 |
| cefpython3 | 31.2 | 55163815 |
Code
See github.com/MartinThoma/algorithms.
Related
- Why are some packages on pypi.python.org/simple, but have no page?
- How can I find out when the last interaction on PyPI happened for a given package?
- What is cheesecake_code_kwalitee_id on PyPI good for?
Further Ideas
- Build a dependency graph: Some of the code was already written. However, one has to download about 25 GB of data, extract it and run over those files. This is quite a bit of work.
- Analyze package quality
- Missing requirements
- Missing metadata / description
- Missing documentation
- PEP8
- Code duplication
- Malicious package search:
- Check which package names are prefixes of other package names.
- Find packages which upload data (dropbox?)
- Find pacakges which remove data from your file system