Celery is a task queue. I was experimenting with it today and want to share some insights.
The Problem
Think of YouTube. Users can upload videos, but before they are shown on the platform they need to get processed. Converting the format, checking for illegal content. This takes a considerable amount of time, so you don't want to let the user stare at a loading screen while you create the backup. So simply having a synchronous call is not working, as those tasks can easily take more than one minute and thus the user might get a timeout. And for sure the user would not like it, if he didn't get any feedback. Also, it might create considerable work and thus you might not want to run it on the same machine.
Solution 1: Conversion Server
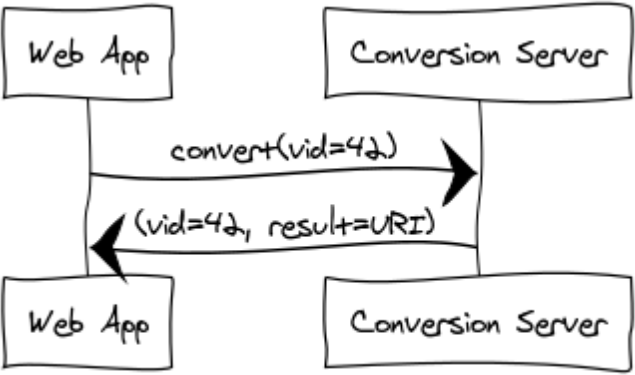
To solve the load and the waiting time problem of the file conversion, we can create a "conversion server". Another machine which takes care of file conversions. Then instead of letting the user wait, we just tell him "conversion is in progress". We make a call to the conversion server with our video id (vid) and wait for the response.
Then we need to somehow call that conversion server. There are several approaches to this:
Synchronous call: We could make a small REST API, but then we would again have the problem that the conversion can take arbitrary long.
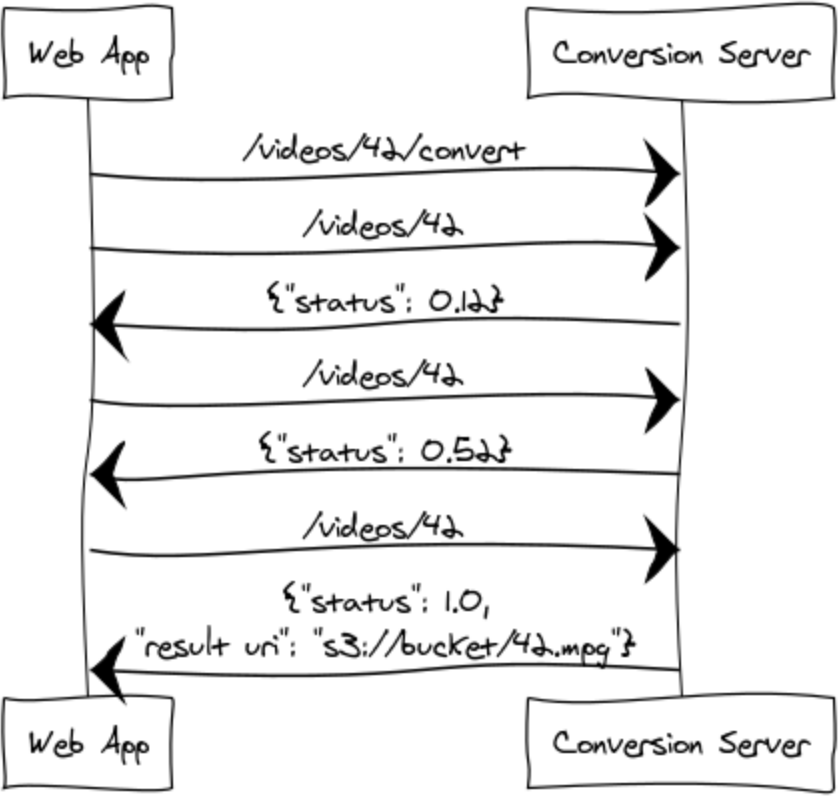
Polling: We could make the web app poll, hence give the conversion server
/videos/<id> and let it return {"status": 0.0}, {"status": 0.5}, ...,
{"status": 1.0, "result_uri": "s3://bucket/42.mpg"}. The disadvantage of
polling is that the web app needs to administrate it. For example, maybe you
want to send the user an e-mail once the conversion is done. You want to send
this e-mail ASAP. So you need to keep polling once the request was sent. During
peak times the number of videos in the conversion queue might get longer and
thus we might end up polling a lot of videos, putting unnecessary load on the
(internal) API of the conversion server.
Callback: Instead of having to ask again and again if the conversion is done, we could give the conversion server a callback URL. Once it is done, it calls the callback back. Hence callback. It works like this:

Solution 2: Message Queue
All three variants of the first solution have one fundamental problem: They don't scale well. Assume suddenly you get from several dozend users to tens of thousands. You will have peak times during which you need to convert way more videos. So you would like to spin up new instances and basically be able to do double the work with double the amount of machines.
How would you do that, starting with a single conversion server?
You would probably create a conversion service:
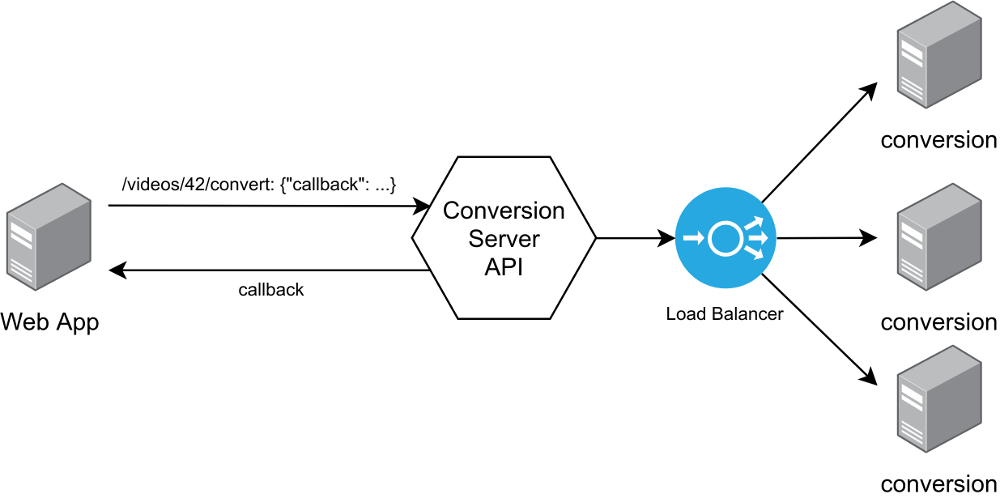
Here the API and the load balancer are overhead. And it is not clear how the "load balancer" would actually work.
Just store the kind of work you want to do somewhere and let "workers" pick up the task. This means you need to pass messages between the web app which contains the upload form / the dashboard for the user and between the workers.
Instead of having the API and the load balancer, you can use a message broker system like RabbitMQ, Redis or Amazon SQS (code sample). The core of those message broker systems is that you can send and receive messages. Sometimes you send it to a topic, in other system it is called a queue. Consumers / clients can read / listen to those queues / topics.
Celery
Celery is a task queue. While not being to deep in the topic, I would say the main advantage of celery compared to usuing the message brokers directly is simplicity. It's easier to use than rabbitmq directly. Additionally, you get flexibility to change the message broker.
It comes with a monitoring tool called flower.
Structurally, my app looked like this:
.
├── celery_worker.py
├── docker-compose.yml
├── Dockerfile
└── web
├── Dockerfile
├── my_project
│ ├── app.py
│ ├── config.py
│ ├── __init__.py
│ ├── main (other flask Blueprints look similar)
│ │ ├── __init__.py
│ │ ├── routes.py
│ │ ├── static
│ │ └── templates
│ ├── models.py
│ ├── static
│ ├── templates
│ └── wsgi.py
├── Makefile
├── setup.cfg
└── setup.py
And I ran it either with docker-compose up or via
celery -A celery_worker.py worker --loglevel=debug
In the following, I give some details about how I adjusted the listed files.
setup.py
Add the new requirement: celery==4.3.0
docker-compose.yml
I've added the following lines:
version: "3"
services:
broker:
image: "rabbitmq:3-management"
container_name: broker
ports:
- "5672:5672"
- "15672:15672"
volumes:
- 'rabbitmq_data:/data'
flower:
image: mher/flower
container_name: flower
command: ["flower", "--broker=amqp://guest:guest@broker:5672//", "--port=8888"]
ports:
- 8888:8888
worker:
container_name: worker
build: .
depends_on:
- broker
links:
- db
environment:
CELERY_HOST: broker
MYSQL_PORT: 3306
MYSQL_ROOT_PASSWORD: foo
MYSQL_DATABASE: bar
MYSQL_HOST: db
volumes:
rabbitmq_data:
Of course, there is also the "web" service which I cropped out here for keeping it simple.
config.py
I've added the following:
CELERY_HOST = os.environ.get("CELERY_HOST", "localhost")
CELERY_BROKER_URL = "amqp://guest:guest@{host}:5672//".format(host=CELERY_HOST)
CELERY_BACKEND = "sqlalchemy"
CELERY_RESULT_DBURI = "sqla+" + SQLALCHEMY_DATABASE_URI
app.py
I followed the application factory pattern (create_app). On the global level
of app.py (not hidden in a function), I've added:
from celery import Celery
celery = Celery(__name__, broker=config.CELERY_BROKER_URL)
and within the create_app:
def create_app(config=None):
# some stuff ...
app = Flask(__name__, template_folder="templates", static_folder="static")
# some stuff ...
celery.conf.update(app.config)
celery_worker.py
#!/usr/bin/env python
from my_project.app import celery, create_app
app = create_app()
app.app_context().push()
Dockerfile
FROM python:3.7-slim
LABEL maintainer="[email protected]"
LABEL description="This is for executing a celery worker"
# Copy projects code
COPY web/ /opt/app
COPY celery_worker.py /opt/app
WORKDIR /opt/app
RUN pip install -e . --no-cache-dir
# Start worker
ENTRYPOINT ["sh", "-c"]
CMD ["celery -A celery_worker.celery worker --loglevel=debug"]
Tasks
In one of the routes.py:
from my_project.app import celery
@backup.route("/videos/<vid>/convert")
@login_required
def convert(vid):
"""Convert a video. This can take time"""
flash("Started converting video", "info")
convert_video.delay(vid) # returns almost instantly
@celery.task(name="convert_video")
def convert_video(user_id):
# Executing this is what takes long
# ... put the file conversion in here!
return 42
See also
- Flask: Celery Background Tasks
- The Flask Mega-Tutorial Part XXII: Background Jobs by Miguel Grinberg
- Why use Celery instead of RabbitMQ?
- Is there any reason to use RabbitMQ over Kafka?