"Data is the new oil", "we need to be data driven", "we need to apply AI to keep being competitive" are some of the prashes I hear a lot. As I haven't seen yet a clear article pointing out what is done with the data ... here you are 🙂
Why it's complicated
Coorporations have a lot of data which is analyzed under different aspects all the time. Micro services are built which have their own data flows, applications and services are updated while they are running. Bugs get fixed. All of this makes the data very heterogenous.
Data quality problems include:
- Mixed attribute availability: Changes and bugs lead to NULL values.
- Semantic Changes: The applications which produce the data might change. Maybe you have "price" column somewhere. At one point it included tax, at another it doesn't. Time might be local, server and UTC. Durations might be seconds and milliseconds.
- Consistency: The data format might change. Maybe the user name is sometimes "FIRSTNAME LASTNAME" and in other cases "LASTNAME, FIRSTNAME".
- Duplicates: Some entries might be duplicated, e.g. multiple form submission.
Engineering problems include:
- Big Data: The amount of data might be bigger than what fits into memory. Maybe even bigger than what fits on a single machine.
- Fast Data: The incoming data might need to be processed in a few milliseconds.
- Privacy: How do we make the platform GDPR complient?
- Security: Authentifiction and Authorization
Data Warehouse
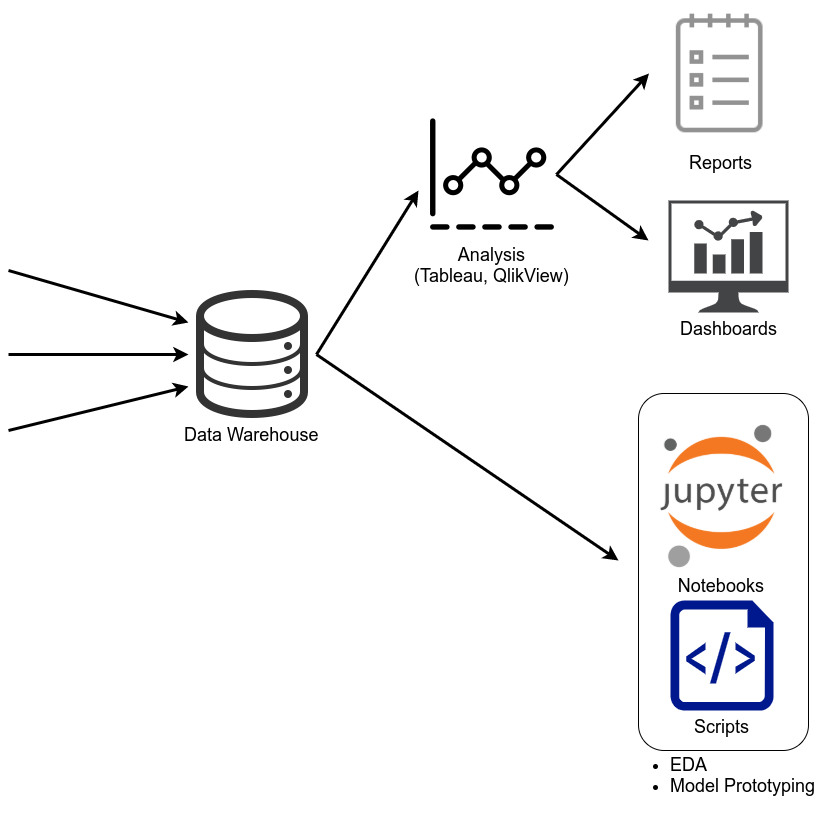
If you have many different data sources and you want to analyze them often, you want a Data Warehouse (DWH). A central place where the data lives. It is likely not completely recent, but should not be too old either. One Data Warehousing solution as a service is Snowflake. Amazon Redshift is another one (promo video). You can execute SQL queries in those warehouses. So you can already make use of that data to answer simple questions.
Reports and Dashboards
Sometimes a table as a result is not enough. You need graphics. The first step might be Excel, but very often this is cumbersome as the data load is too big, as one needs to download the data from the warehouse. Then Tableau (promo video) and QlikView (promo video) come into play. The Buzzword here are data driven and self-service BI. People using this software are often called Business Analysts and work in an BI department. They usually create dashboards and reports which drive business decisions.
If the company has a lot of very different data, a data dictionary might help. In the simplest case, it could be a word document. A bit more advanced would be to use the comment attribute for columns in databases. Then there are tools like dataedo as well.
POC: Model creation
Sometimes, analysis of the past behavior is not enough. You need a predictive model for future cases. Maybe even have it as a part of a customer-facing product. Now you need a Data Scientist. The work starts at the warehouse. As the warehouses and QlikView / Tableaus options are too limited, the data scientist gets a dump of the relevant parts. This might include some aggregtions, filtering and unions in the warehouse before, but at some point it will likely be imported in an environment where Python can be used. The Data Scientist analyzes the data, e.g. with a Jupyter Notebook. Usually the data contains many problems like unrealistic values or missing data (NULL values). Then the model creation part starts. This could still happen in the Notebook. To solve the prediction task, the data scientist might use models such as SVMs, neural networks or Random Forests.
The data scientists create a Proof of Concept (PoC). The model is not in a state to be used directly in production, because a lot of the cables might not be connected. But it should be clear from the PoC if the data allows building the kind of model you want to have. A valid outcome of the PoC is that it is (currently) not possible.
The two parts that can consume arbitrary much time are data cleaning and model optimization. Even after the PoC. If you're interested in that topic, ping me in the comments.
From POC to MVP
Once the model is ready and seems to work well enough for practice, a Data Engineer gets involved. The mentioned delay a Data Warehouse often has and the different kind of workload the model typically requires makes it necessary to get the data from a different source. If it should be event-based, it might be Apache Kafka for messaging or Apache Flink. The important point to notice here is that machine learning models typically contain two seperate phases: Model training and model inference. At training time, one needs to process a lot of data and needs a lot of computational power. At inference time, each requests data is tiny. The amount of computation necessary is small. So it is a mixed execution mode: Regularly re-train a model in a batch-way and have a continuously running service for inference. They might build things like Kappa Architectures or Lambda Architectures. To do so, many cloud technologies can be used (see "Cloud Service Overview").
If you wish to get more information about this part, ping me in the comments.
Cloud Service Overview
The following cloud services might be used to create services which run in the cloud:
- AWS Lambda Compute
- Running small and short scripts after a triggering event. Has a delay of a couple of seconds. Provides Computational Resources.
- AWS Cloudformation
- Infrastructure as Code (IaC) Tool
- AWS EC2 Compute (AWS)
- provides scalable computing capacity;
- AWS S3 Storage
- Store Files
- AWS InnoDB Storage
- Key-Value Store
- AWS SSM Storage
- Store Passwords and configuration
- AWS Athena
- run interactive queries directly against data in Amazon S3
- AWS Kinesis
- a real-time data processing platform
- AWS Redshift
- fully managed, petabyte-scale data warehouse to run complex queries on collections of structured data
- Amazon EMR
- deploy open source, big data frameworks like Apache Hadoop, Spark, Presto, HBase, and Flink
See also
There are a couple of follow-up topics which might result in:
- How to deploy machine learning models
Stuff I would like to share / look into for enhancing this article:
- Top 20 Free, Open Source and Premium Stream Analytics Platforms
- PyBay2018: How to Instantly Publish Data to the Internet with Datasette
- Reproducibility in Machine Learning
- Carl Anderson: Data Dictionary: a how to and best practices
- Connecting Scientific Models across Scales & Languages w/ Python, SciPy 2018.
- Mark Keinhörster: Production ready Data-Science with Python and Luigi, PyData 2018.
- Dr. Benjamin Weigel: Deploying a machine learning model to the cloud using AWS Lambda, PyData 2018.
- Dmitry Petrov: Data versioning in machine learning projects PyData 2018.
- Why Not Airflow?
- How to deploy a Docker app to Amazon ECS using AWS Fargate, 2018.
- Deploying on AWS Fargate using Cloudformation, 2018.
- Jen Underwood: Why You Need a Data Catalog and How to Select One
- Nick Schrock: Introducing Dagster, 2019.
- Github Issue: Dagster vs. Rest, 2019.