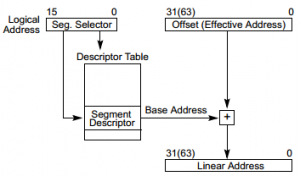
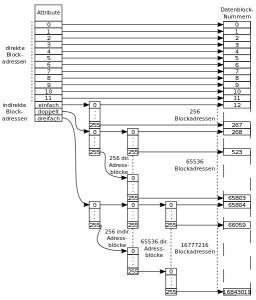
Wenn ich im Folgenden eine Seitenzahl angebe, dann ist damit "Operating System Concepts" von Silberschatz gemeint (ISBN 0-471-69466-5):
Themen
- Process Coordination:
- Shared Memory
- Critical-Section Problem: Peterson's Solution, Synchronisation
- Deadlock, Starvation
- Process Management
- Process Scheduling
- Process States: new, ready, running, waiting, terminated
- Process Control Block: Folie 6/65 slide_proc_management
- Memory Management
- Globale / lokale Seitenersetzungsstrategie
- Equal allocation
- Slab allocator
Begriffe
Folgende Begriffe muss man kennen und erklären können:
- Critical Section und Race Condition
- Semaphor: counting Semaphores, binary Semaphores und Mutex Locks → Antwort auf S. 200f
- Dining-Philosophers Problem → Antwort auf S. 207f
- Deadlock, Starvation
- Safe State
FAQ
- Wie funktionieren Bitmasken und insbesondere ~, &, |?
- Nenne ein reales Beispiel, bei dem eine Race-Condition auftreten könnte.
- Welche Probleme hat Contiguous Allocation? → Antwort
- Priority Scheduling
- Round Robin
- Multilevel Feedback Queue
- Lottery Scheduling
- PSJF
- FCFS
- Mutual exclusion: Only one thread can be in the CS at a time.
- Progress:
- If no thread is in the CS one of the threads trying to enter will eventually get in
- Threads that are not trying to enter do not hinder processes that try to enter from getting in
- Bounded waiting: Once a thread starts trying to enter the critical section, there is a bound on the number of times other threads get in.
- Interrupts deaktivieren (nur im Kernel-Space, nur Single-Core)
- Spezielle atomare Instruktionen:
- Semaphor (wait und signal)
- Monitor
- Algorithmus von Peterson
- Mutual exclusion: Eine Ressource kann nicht gleichzeitig von mehreren Prozessen benutzt werden
- Hold and wait: Ein Prozess, der bereits mindestens eine Ressource hält, wartet auf mindestens eine andere Ressource
- No preemption: Zugeteilte Ressourcen können einem Prozess nicht wieder entzogen werden. Er muss diese selbst freigeben.
- Circular wait: Es gibt eine Menge von Prozessen $\{P_0, P_1, \dots, P_n\}$, wobei $P_0$ auf eine Ressource wartet, die $P_1$ hält, $P_1$ auf eine Ressource wartet, die $P_2$ hält, ..., $P_n$ auf eine Ressource wartet, die $P_0$ hält.
- Prevention
- Avoidance
- Detection:
- Prozess abschießen
- Rollback
- Vogel-Strauß-Algorithmus: Der User wird sich schon drum kümmern, z.B. indem er einen Prozess abschießt (
kill -9) oder indem er den PC vom Strom nimmt.
- RAID 0: Striping. Platten werden "aneinandergehängt".
- RAID 1: Mirroring. Daten werden auf mehrere Platten gespiegelt.
- RAID 2: Fehlerkorrigierender Hamming-Code.
- RAID 3: Byteweise Parität.
- RAID 4: Blockweise Parität.
- RAID 5: Blockweise, verteilte Parität.
moose@pc08 ~ $ df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/sda1 303869280 16418288 272015268 6% /
udev 1889040 4 1889036 1% /dev
tmpfs 758712 988 757724 1% /run
none 5120 0 5120 0% /run/lock
none 1896772 772 1896000 1% /run/shm
none 102400 8 102392 1% /run/user
moose@pc08 ~ $ sudo tune2fs -l /dev/sda1 | grep 'Block size'
Block size: 4096
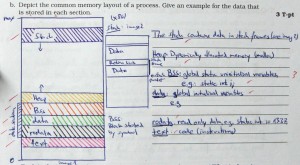
const dabei stehen sollte. Statische Variablen können natürlich geändert werden.
Material
Material zum Üben (also alte Klausuren) gibt es wie immer entweder online oder bei der Fachschaft.
Die Lösungen zu den Klausuren sind passwortgeschützt, aber wenn ihr euch einmal über VPN einloggt, stehen ganz unten auf der Seite die Zugangsdaten.
Das Skript / die Folien sind im VAB.
Folgende Wiki-Artikel und manpages sollte man sich durchlesen:
- Unix-Dateirechte und
chmodsowie mein Artikel.
Als Buch kann ich neben dem Silberschatz folgendes empfehlen: LPIC-1 - Vorbereitung auf die Prüfung des Linux Professional Institute. ISBN 978-3-937514-81-9
Some Random Facts
subl $16, %espallokiert 16 Byte auf dem Stack.
Termine und Klausurablauf
Datum: 18.03.2012 um 14:00 Uhr.
Ort: ich bin im 30.21 Gerthsen (Hörsaalverteilung)
Dauer: 60 Minuten
Punkte: 60
Bonuspunkte: Abhängig von den Punkten im Übungsschein:
- 110 - 129 Punkte: 1 Bonuspunkt
- 130 - 149 Punkte: 2 Bonuspunkte
- 150 - 169 Punkte: 3 Bonuspunkte
- 170 - x Punkte: 4 Bonuspunkte
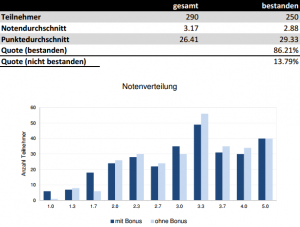
Quelle
Nicht vergessen: Studentenausweis
Einsicht: 09.04.2013 (war seit spätestens 13.02.2013 bekannt)
Ort der Einsicht: 07.07 (Vincenz-Priessnitz-Str. 1, 2.OG, links), Raum 215
Zeit der Einsicht: Je nach Matrikelnummer unterschiedlich.
Ergebnisse
Hängen noch nicht aus (Stand: 15.03.2013)
Hängen nun aus (Stand: 08.04.2013) und sind im VAB verfügbar